
Yann LeCun, director of Facebook’s AI Research Group, is the pioneer of convolutional neural networks. He built the first convolutional neural network called LeNet in 1988. LeNet was used for character recognition tasks like reading zip codes and digits.
In 2012, computer vision took a quantum leap when a group of researchers from the University of Toronto developed an AI model that surpassed the best image recognition algorithms by a large margin.
The AI system, which became known as AlexNet (named after its main creator, Alex Krizhevsky), won the 2012 ImageNet computer vision contest with an 85 percent accuracy.
At the heart of AlexNet was a Convolutional Neural Network (CNN) that roughly imitates human vision. Over the years CNNs have become a very important part of many computer vision applications.
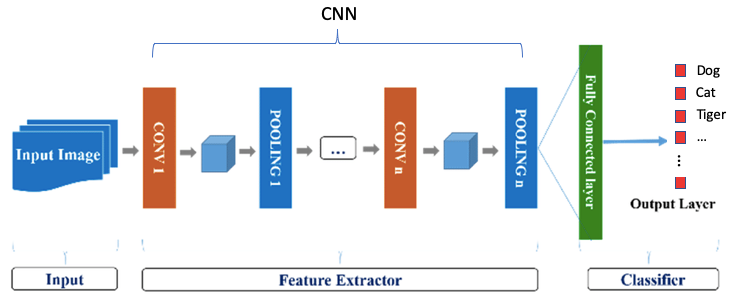
Imagine there’s an image of a bird, and you want to identify whether it’s really a bird or some other object. The first thing you do is feed the pixels of the image in the form of an array (collection of numbers that represent the pixel values of the image) to the input layer of the neural network. The hidden layers carry out feature extraction by performing different calculations and manipulations. There are multiple hidden layers (the convolution layer, the ReLU layer, and pooling layer) that perform feature extraction from the image. Finally, there’s a fully connected layer that classifies/identifies the object in the image.
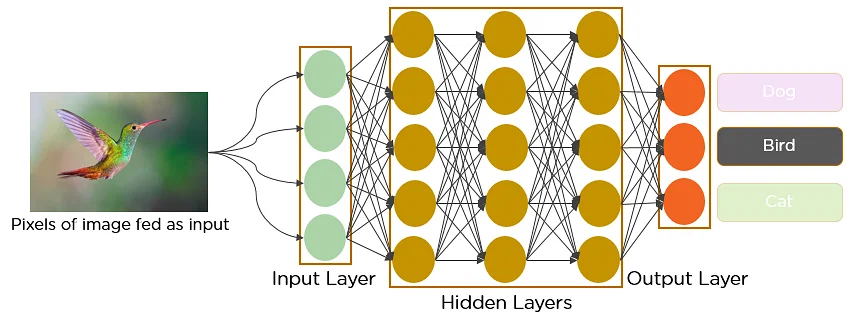
Source: Simplilearn.com
A convolutional neural network is a feed-forward neural network that is generally used to analyze visual images by processing data with grid-like topology. It’s also known as a ConvNet.
CNNs use a special technique called Convolution, a mathematical operation that produces a numerical output that expresses how the shape of one is modified by the other. The role of the CNN is to reduce the images into a form that is easier to process, without losing features that are critical for obtaining a good prediction.
In a CNN, every image is represented in the form of an array of pixel values. For example, in a black-and-white image, each pixel of the image is represented by a number ranging from 0 to 255. Most images today use 24-bit color or higher. An RGB color image means the color in a pixel is a combination of Red, Green, and Blue, each of the colors ranging from 0 to 255.
Simplified illustrative example of encoding the pixels of an image to numerical values:
![]()
To detect images, the CNN will first work to identify edges and shapes using a filter (i.e., kernel), which is simply a 3×3 matrix that is initialized with preset values which will be multiplied by the numerical values of each pixel within the encoded image to obtain the convolved feature. Note: the size of the filter matrix can be adjusted in different models. As the image is passed through the network, it will be applied (multiplied) to more complex filters.
This approach abstracts the numerical values of each pixel image and heightens (via multiplication) the feature that the filter is looking for. Many filters exist within the network, with each maintaining different numerical values in their matrices to identify different elements within the image. In the example below, the filter (Kernel) is seeking “X” related features of an image as identified by the 1s in the filter matrix:
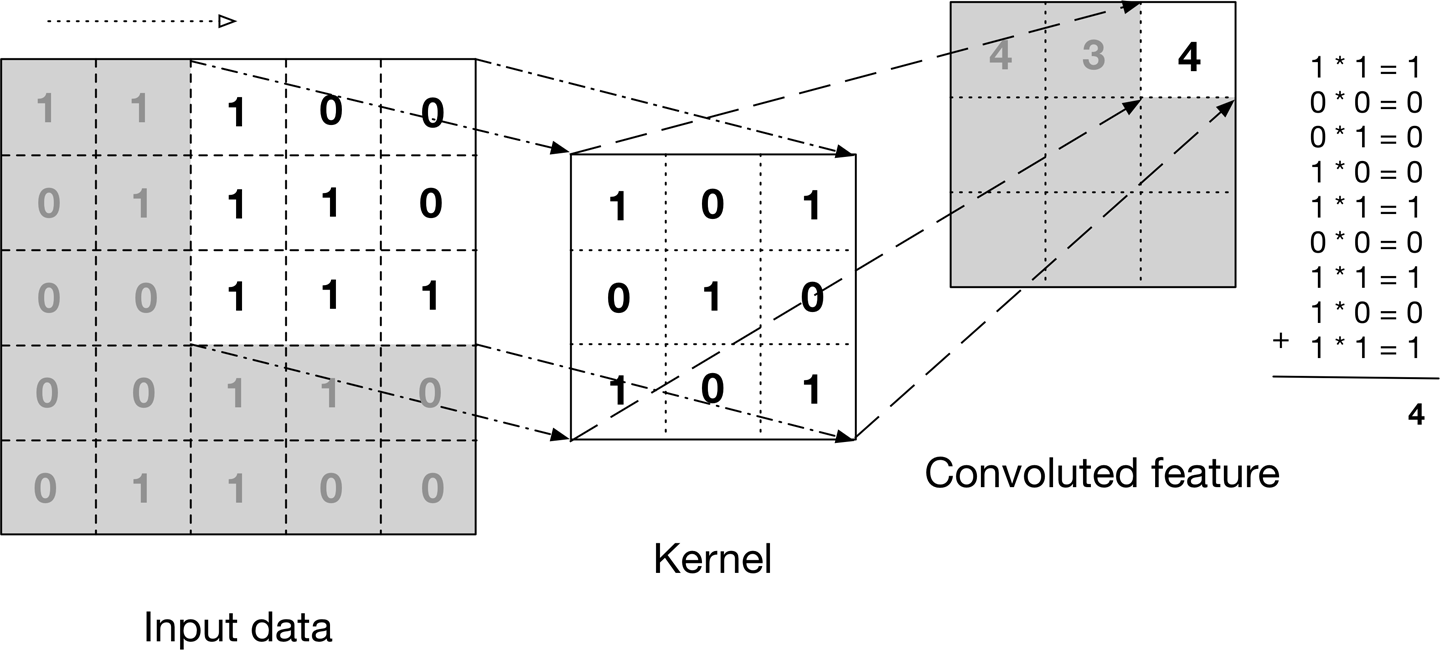
The 3×3 filter moves across the image from left to right and top to bottom, and the product is summed to create a new array, or the convolved feature (feature map), which contributes to the input of the next layer in the network. This process continues until the convolution operation is complete.
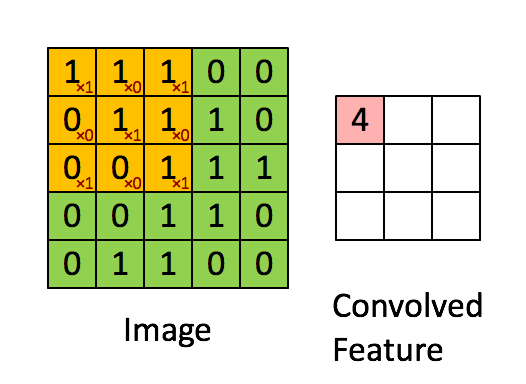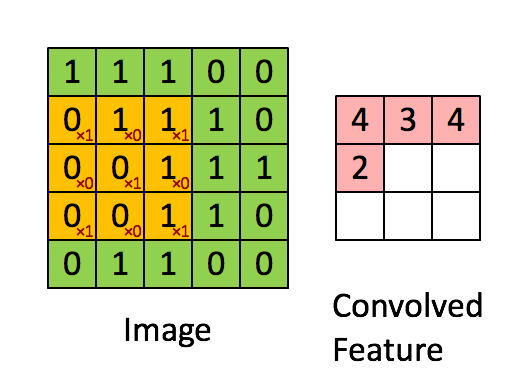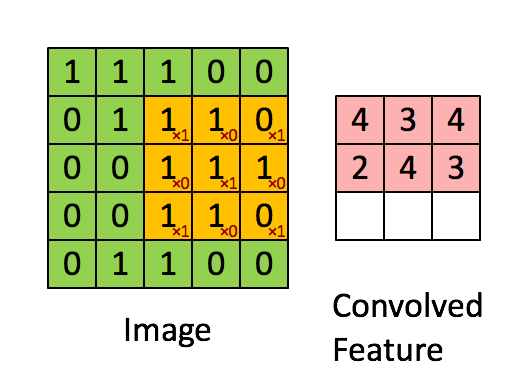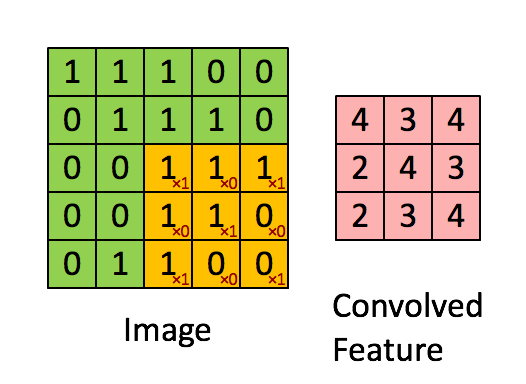
After scanning through the original image, each feature produces a filtered image with high scores and low scores. The filters are the weights and biases. If there is a perfect match, there is a high score in that square. If there is a low match or no match, the score is low or zero.

More filters mean more features that the model can extract However, more features mean longer training time; one is advised to use the minimum number of filters to extract the features.
Hyperparameters can be used to adjust the model including:
- Padding: Adjusting the original image with zeros to fit the feature, or dropping the part of the original image that does not fit and keeping the valid part.
- Stride: Adjusting the number of pixels by which the filter shifts over the input matrix. When the stride is 1, the filters shift 1 pixel at a time.
An RGB image is similar but its pixels consist of three planes (Red (R), Green (G), Blue (B)):
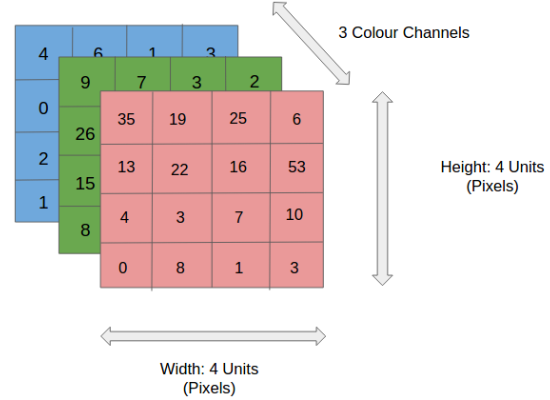
A convolution neural network has multiple hidden layers that help in extracting information from an image. The four important layers in CNN are:
- Convolution layer
- ReLU layer
- Pooling layer
- Fully connected layer
Convolution Layer
As illustrated earlier, this is the first step in the process of extracting valuable features from an image. A convolution layer has several filters that perform the convolution operation. Every image is considered as a matrix of pixel values. The first layer usually extracts basic features such as horizontal or diagonal edges.
ReLu Layer (Activation)
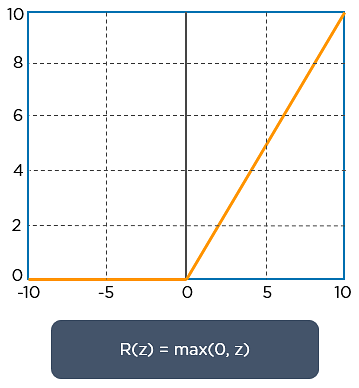
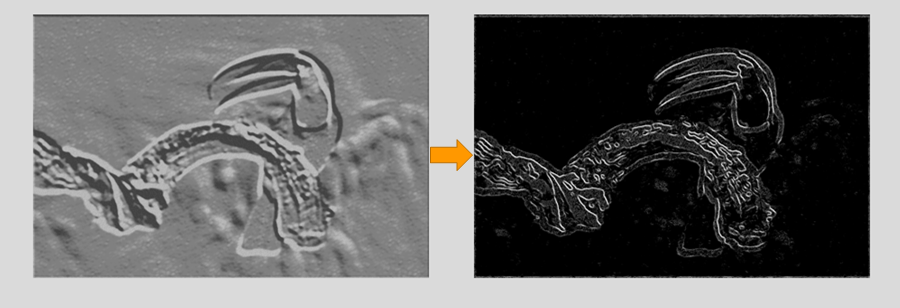
In order to keep the ouputs of the matrix calculations within a specified range, a rectified linear unit (ReLU) activation function is calculated. Once the feature maps are calculated, the next step is to move them to a ReLU layer. ReLU sets all the negative pixels in the convolved matrix to 0. It introduces non-linearity to the network, and the generated output is a rectified feature map. Below is the graph of a ReLU function:
One can see by applying the ReLU formula to remove non-zero numbers, more detail is added to the image:
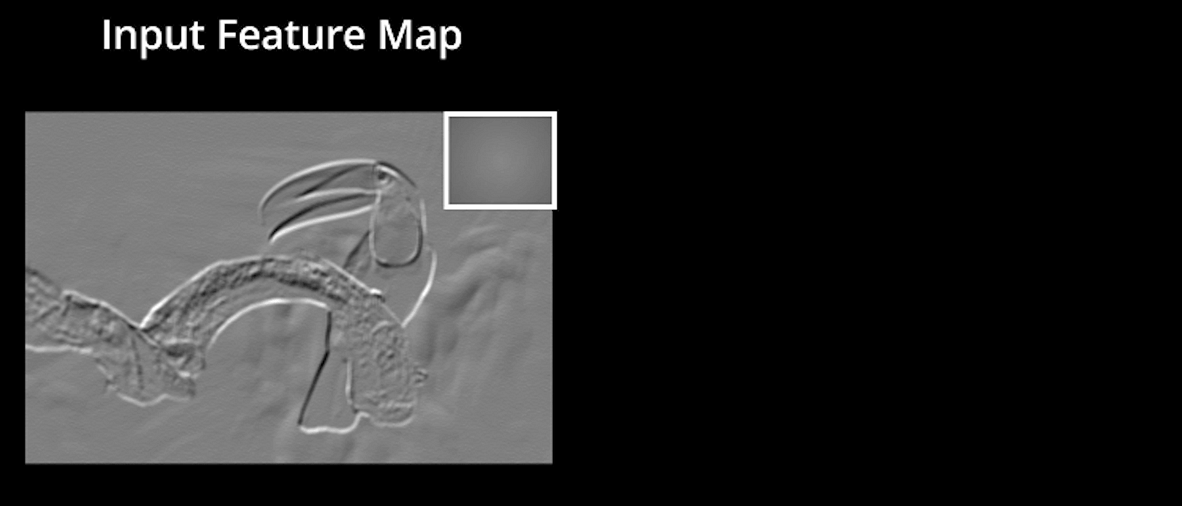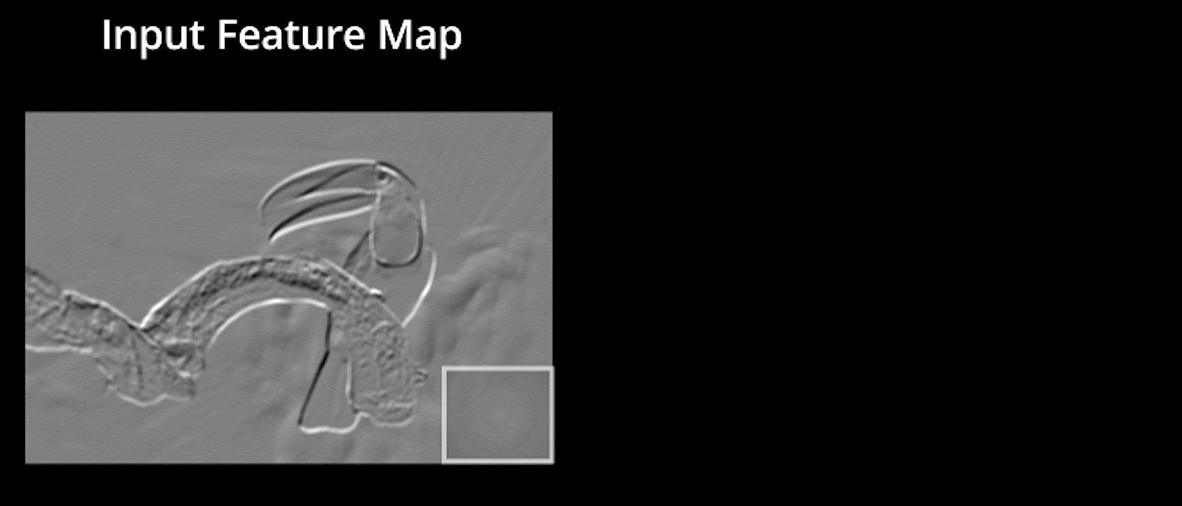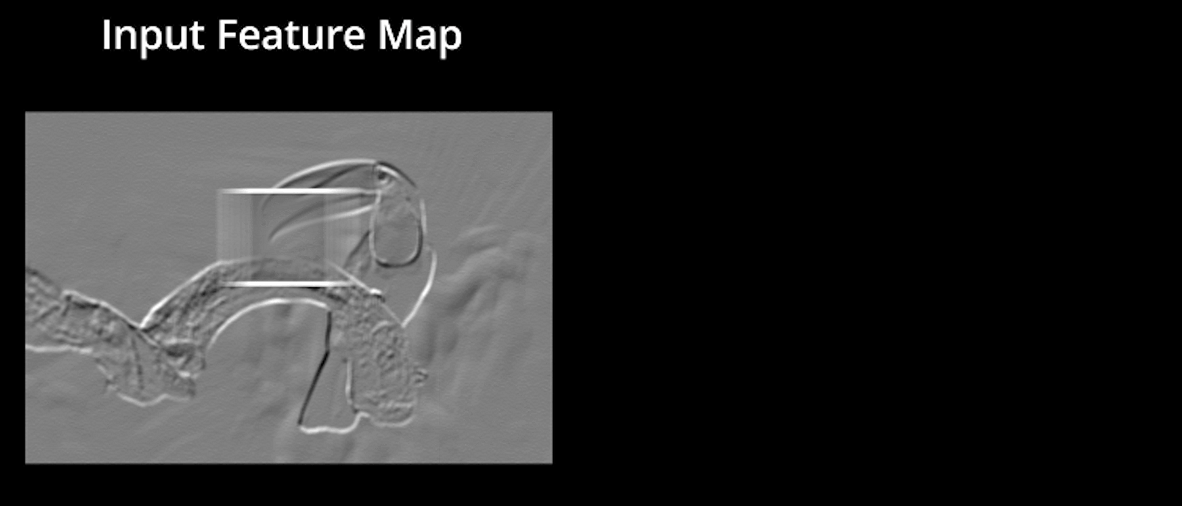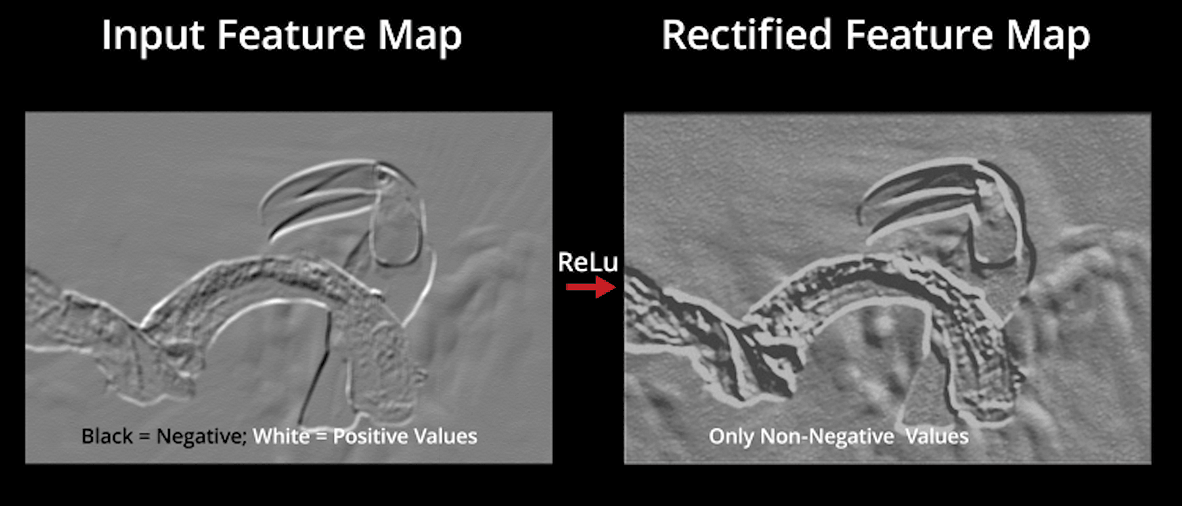
Source: Simplilearn
As mentioned above, the image is processed with multiple convolutions (filters) and ReLU layers for locating more complex features such as corners or combinational edges. As the image moves deeper into the network, each ouput from one layer serves as the input to the next layer enabling the network to identify more complex features such as objects, faces, etc.
Pooling Layer
Pooling is a down-sampling operation that reduces the dimensionality of the feature map and takes the max value of the section within the array to generate a pooled 2×2 feature map. Pooling acts on all the neurons of the feature map.

The pooling layer uses various filters to identify different parts of the image like edges, corners, body, feathers, eyes, and beak. By reducing the dimensions, it decreases the computational power required to process the data.
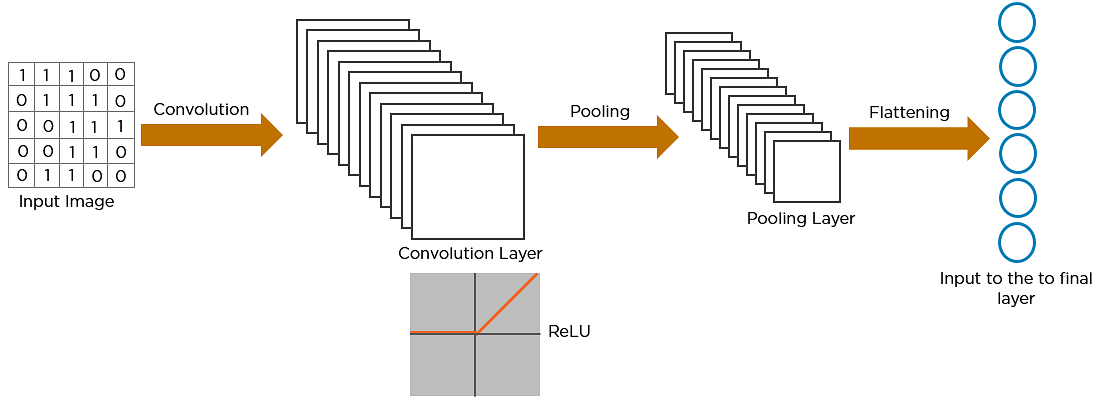
The convolution, ReLU and pooling actions are executed numerous times to extract all the features of an image before it is passed to the fully connected layer.
Fully Connected Layer
The fully connected layer connects every neuron in one layer to another layer. It begins the process of inputting the features of the image into the neural network for image classification.
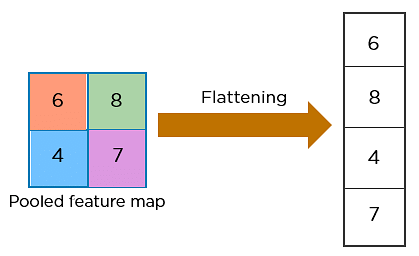
Flattening is used to convert all the resultant 2-dimensional arrays (filters) from pooled feature maps into a single long continuous linear vector.
The flattened matrix is fed as input to the fully connected layer to classify the image.
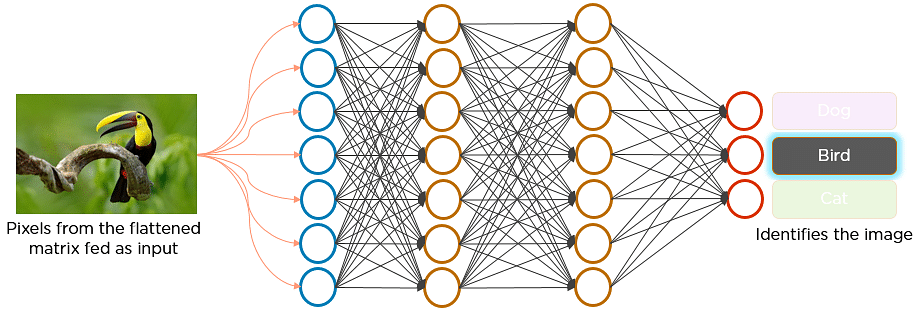
The values of the activation map of the final convolution layer is inputted into the fully connected layer to classify the image. Through its own set of weights and biases, the classification layer outputs a set of confidence scores (values between 0 and 1) in the form of a one-dimensional matrix that specifies how likely the image is to belong to a “class.” For instance, in a ConvNet that detects cats, dogs, and horses, the output of the final layer will output the probability that the input image contains any of those animals. CNN training and model refinement is performed using a loss function calculation and backpropagation to refine the model weights.
Despite the power and resource complexity of CNNs, they provide in-depth results. At the root of it all, it is just recognizing patterns and details that are so minute and inconspicuous that it goes unnoticed to the human eye. But when it comes to understanding the contents of an image it fails.
AI INFLUENCERS
John Carmack ![]()
![]()
Clem Delangue ![]()
Timnit Gebru ![]()
![]()
Jensen Huang ![]()
![]()
Lila Ibrahim ![]()
![]()
Robert Miles ![]()
![]()
Kevin Scott ![]()
![]()
AI MODELS
Popular Large Language Models
ALPACA (Stanford)
BARD (Google)
Gemini (Google) ![]()
GPT (OpenAI) ![]()
LLaMA (Meta) ![]()
Mixtral 8x7B (Mistral)
PaLM-E (Google)
VICUNA (Fine Tuned LLaMA)
Popular Image Models
Stable Diffusion (StabilityAI)
Leaderboards
