
Transformer neural networks and large language models (LLMs) have ushered in an exciting time for Artificial Intelligence. Despite the incredible advancements, LLMs still face a number of different challenges that prevent them from providing greater value to its users:
- They are static – LLMs are “frozen in time” and lack up-to-date information. For example, ChatGPT was trained on data up to September 2021. Consequently, ChatGPT alone is not able to provide information regarding details or events that occurred after the cutoff training date. After OpenAI finished training the ChatGPT foundation model (FM) 2021, it received no additional updated information about the world such as world events, weather systems, new laws, the outcomes of sporting events, etc. If one prompts ChatGPT about something that occurred last month, it will not only fail to answer the question factually; it will likely hallucinate, generating a plausible yet made up and false response.
- They lack domain-specific knowledge – LLMs are trained for generalized tasks, and they do not know or have access to an any private data. Although an LLM’s base corpus of knowledge is impressive, it does not know the specifics that are unique to a specific organization or person.
- They function as “black boxes” – because of the inherent way LLMs work and the way they are trained, it is not easy to understand which sources an LLM was considering when it generated its response.
- They are inefficient and costly to produce – It costs millions of dollars to train the state of the art (SOTA) LLMs and few organizations have the financial means to develop and train models. Hardly any company can afford to train the model each and every time new information is added to a corpus of knowledge.
Foundation models can be fine-tuned on labeled, domain-specific knowledge to address a variety of tailored tasks with some additional fine-tuning. Although fine-tuning can enhance the output of a model, it does not address many of the other challenges including cost, source citation and applying ever-changing current world information.
The image below depicts a prompt to an LLM that does not have access to specific information:
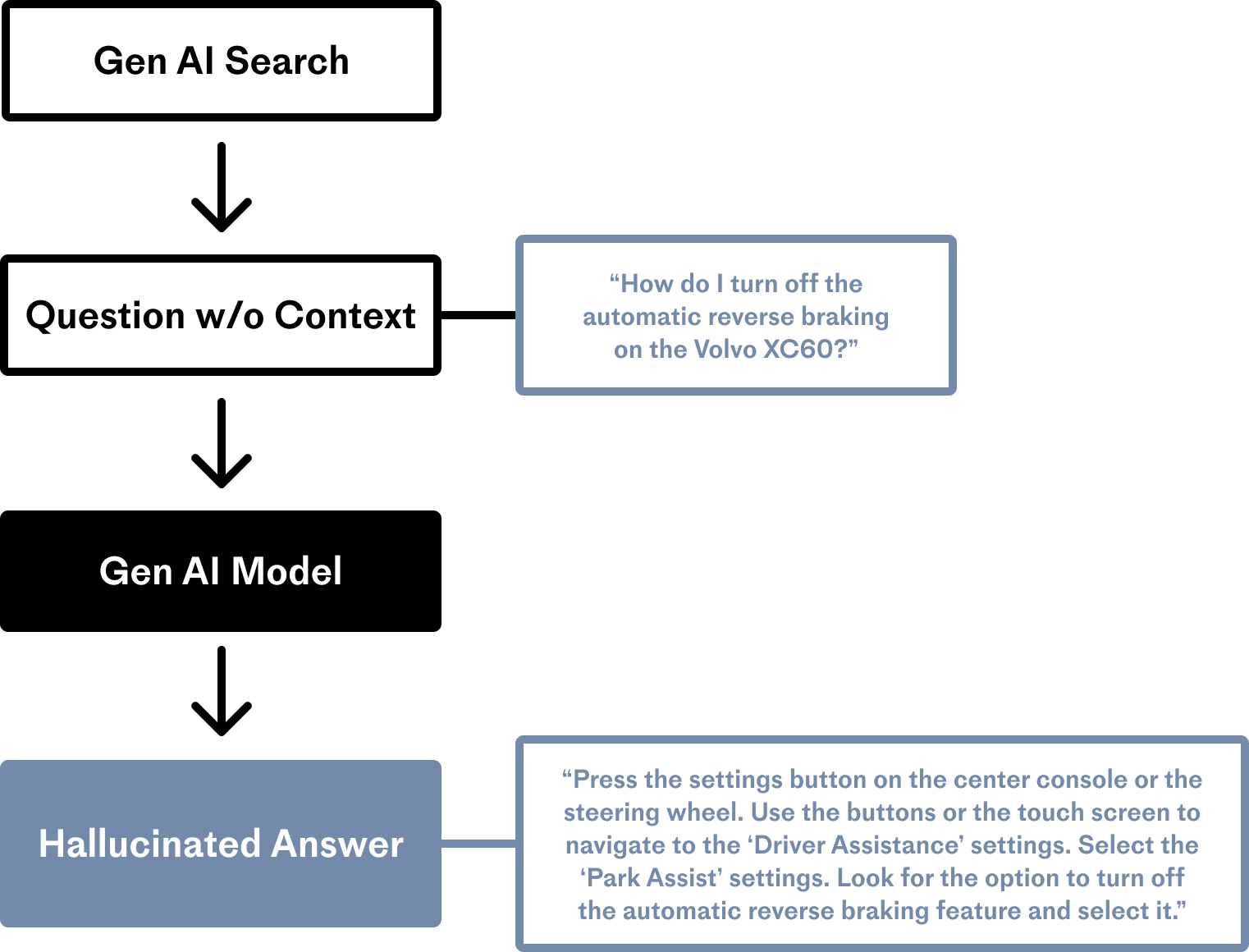
Source: Pinecone
In the example above, although the LLM has no idea how to turn off reverse braking for that car model, it performs its generative task to the best of its ability anyway, producing an answer that sounds grammatically solid – but is unfortunately flatly incorrect.
In a 2020 paper, Meta came up with a framework called retrieval-augmented generation (RAG) to provide LLMs with access to information beyond their training data. RAG allows LLMs to build on a specialized body of knowledge to answer questions in more accurate way.
RAG Overview
The concept of Retrieval Augmented Generation was introduced to help LLMs overcome these issues. Retrieval Augmented Generation works by fetching up-to-date or context-specific data from an external database and makes the content available to an LLM to support the generation of a response. The grounding of the model on external sources of knowledge to supplement the LLM’s internal representation of information has proven to boost the performance and accuracy of LLM applications by enabling the following:
- Make LLMs dynamic – by leveraging RAG to pull in real-time information such as business data or specific information related to a prompt, LLMs are able to generate more accurate and relevant responses and mitigate the likelihood of hallucinations. For example, a generative AI model supplemented with a medical index could be a great assistant for a doctor or nurse. Financial analysts would benefit from an assistant linked to market data. Almost any business can turn its technical or policy manuals, videos or logs into resources called knowledge bases that can enhance LLMs. These sources can enable use cases such as customer or field support, employee training and developer productivity.
- Make LLMs more trustworthy and accurate – in addition to addressing the recency and domain-specific data issues, RAG allows GenAI applications to access the most current, reliable facts and provide the sources that contributed to the response, much like research papers will provide citations for where they obtained an essential piece of data used in their findings. RAG ensures that LLM generated responses can be checked for accuracy and can ultimately be trusted.
- Make LLMs more cost effective to operate – the process of training a generalized LLM to refine its parameters is time-consuming and costly. Updates to the RAG model are just the opposite. New data can be embedded and stored in a database which can then be utilized by the LLM on a continuous, incremental basis. Moreover, the answers generated by the LLM can also be fed back into the RAG model, improving its performance and accuracy, because, in effect, it knows how it has already answered a similar question.
How RAG Works
RAG has two phases: retrieval and content generation. In the retrieval phase, algorithms search for and retrieve snippets of information relevant to the user’s prompt or question. In an open-domain, consumer setting, those facts can come from indexed documents on the internet; in a closed-domain, enterprise setting, a narrower set of sources are typically used for added security and reliability.
For an LLM to leverage the supplemental data, the data must be in a format that the LLM can understand. LLMs use data that are encoded into tokens in the form of vectors which can be thought of as a matrix of numbers. A vector represents the meaning of the input text, the same way another human would understand the essence if you spoke the text aloud. Leading LLMs utilize vectors with over 512 values within each vector.
As a simple example, the vector value for the word “apple” may be [24, 61, 68, 88, …., n]
When information is encoded into vectors, it is termed an embedding. Embeddings are encoded by a specialized embedding LLM that converts data into vectors: arrays, or groups, of numbers and stores the values in a specialized database known as a vector database. The value of the embeddings denotes the relationship between the embedded data utilizing the 512+ values of the vector (e.g., instructions, news, words, etc.).
The image below illustrates at a high level the process by which the driver’s manual of an automobile is encoded into an embedding (vector) and stored within a vector database:
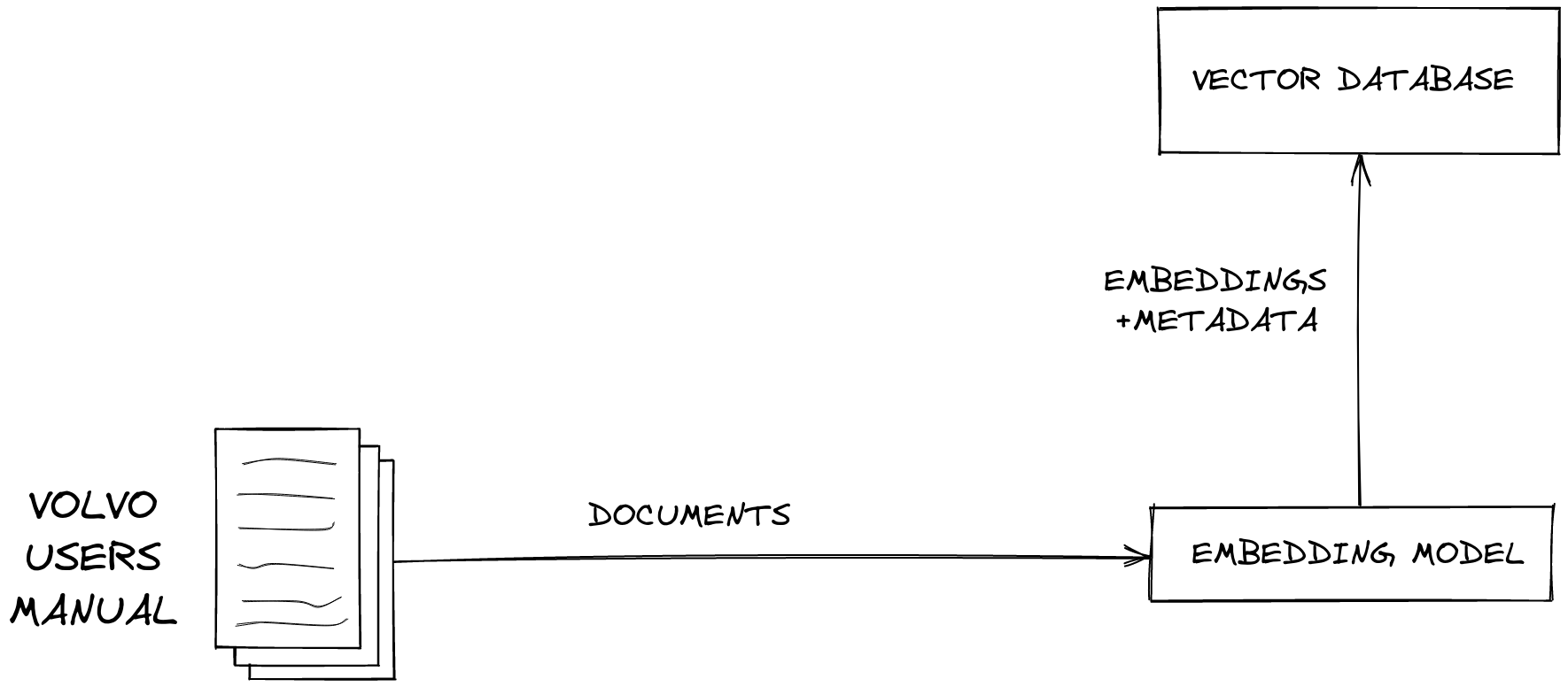
Source: Pinecone
When a user prompts an LLM, the model attempts to understand the true meaning of the query and retrieve relevant information instead of simply matching keywords in the user’s query. This process, known as semantic search, aims to deliver results that better fit the user’s intent, not just their exact words.
The image below visualizes the RAG flow to support generation when a vector database is used to improve the response using relevant and current information:
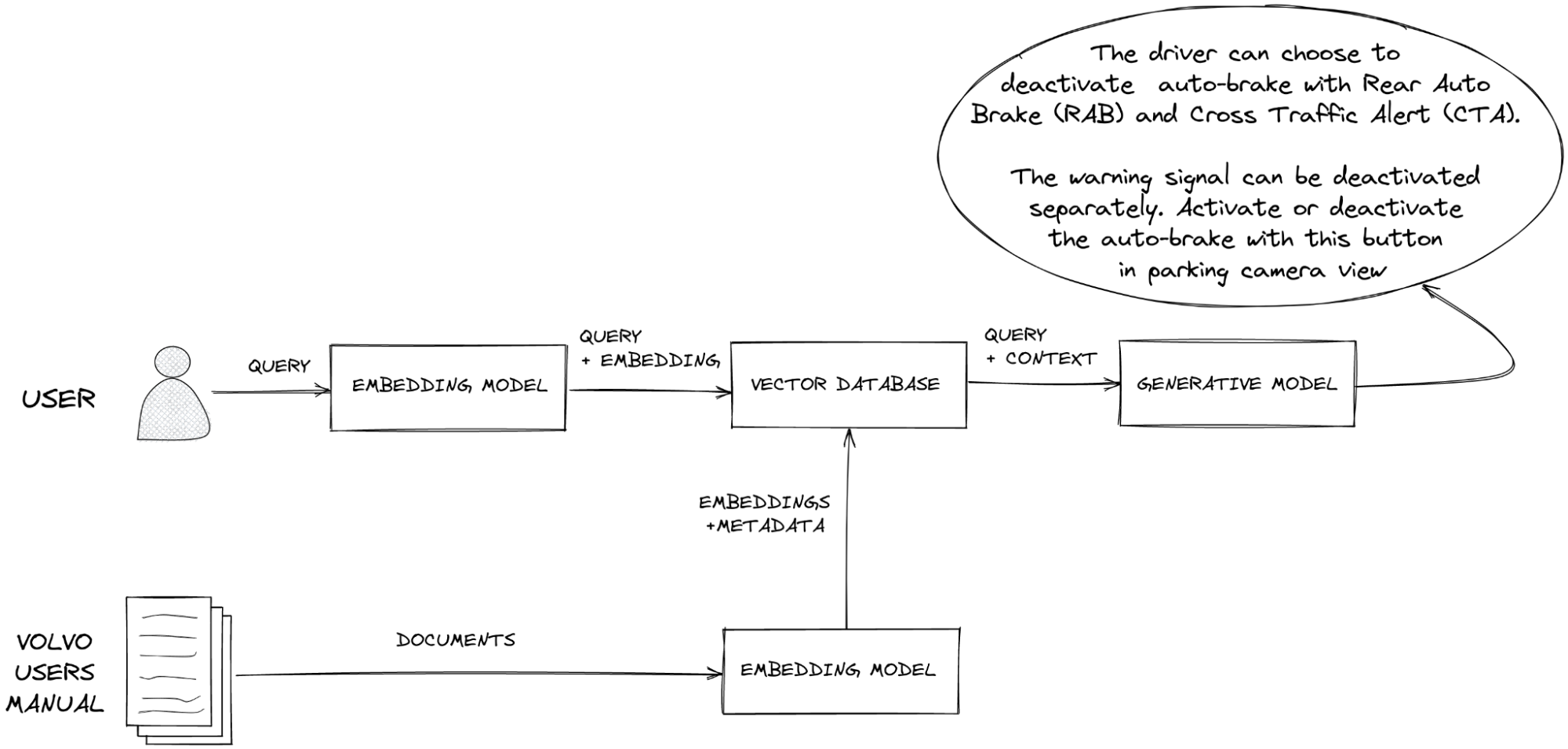
Source: Pinecone
The vector database performs a “nearest neighbor” search, finding the vectors that most closely resemble the user’s intent. When the vector database returns the relevant results, the application provides them to the LLM via its context window, prompting it to perform its generative task. Because the LLM can now easily determine the specific data that it was fed from the vector database to support the response, it can cite the source in its answer. If generative AI’s output is inaccurate, the document that contains that erroneous information can be quickly identified, corrected, and re-fed into the vector database.
AI INFLUENCERS
John Carmack ![]()
![]()
Clem Delangue ![]()
Timnit Gebru ![]()
![]()
Jensen Huang ![]()
![]()
Lila Ibrahim ![]()
![]()
Robert Miles ![]()
![]()
Kevin Scott ![]()
![]()
AI MODELS
Popular Large Language Models
ALPACA (Stanford)
BARD (Google)
Gemini (Google) ![]()
GPT (OpenAI) ![]()
LLaMA (Meta) ![]()
Mixtral 8x7B (Mistral)
PaLM-E (Google)
VICUNA (Fine Tuned LLaMA)
Popular Image Models
Stable Diffusion (StabilityAI)
Leaderboards
