
Generative Adversarial Networks (GANs) were introduced in 2014 by Ian J. Goodfellow and co-authors. GANs perform unsupervised learning tasks in machine learning. They can be used to generate new examples that plausibly could have been drawn from the original dataset. Today, GANs serve as the model behind image generation services including Stable Diffusion and Midjourney.
GANs consist of two neural networks that automatically discover and learn the patterns in input data: a Generator G(x) and a Discriminator D(x). Both networks play an adversarial game against one another – the generator’s aim is to fool the discriminator by producing data that are similar to those in the training set while the discriminator will try not to be fooled by identifying fake data from real data. Both of the networks work simultaneously to learn and train complex data like audio, video, or image files.
A GAN can be compared to the cat-and-mouse game between a cop and a counterfeiter, in which the counterfeiter learns to pass fake currency and the cop learns to spot it.
Both are dynamic; for example, the cop is learning as well (to continue the analogy, perhaps the central bank is flagging banknotes that snuck through), and each side continuously escalates their learning of one another’s strategies.
GANs typically work with image data and use Convolutional Neural Networks, or CNNs, as the generator and discriminator models. The reason for this may be both because the first description of the technique was in the field of computer vision and used CNNs and image data, and because of the remarkable progress that has been seen in recent years using CNNs more generally to achieve state-of-the-art results on a suite of computer vision tasks such as object detection and face recognition.
Generators
A Generator in GANs is a neural network that creates fake data and is trained using the discriminator network to improve its ability to generate plausible data. The main aim of the Generator is to make the discriminator classify its output as real.
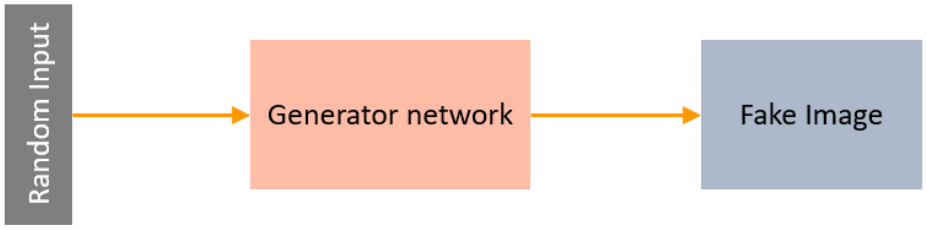
Source: Simplilearn
The part of the GAN that trains the Generator includes:
- noisy input vector
- generator network, which transforms the random input into a data instance
- discriminator network, which classifies the generated data
- generator loss, which penalizes the Generator for failing to dolt the discriminator
Backpropagation and gradient descent is used to adjust each weight by calculating the weight’s impact on the output.
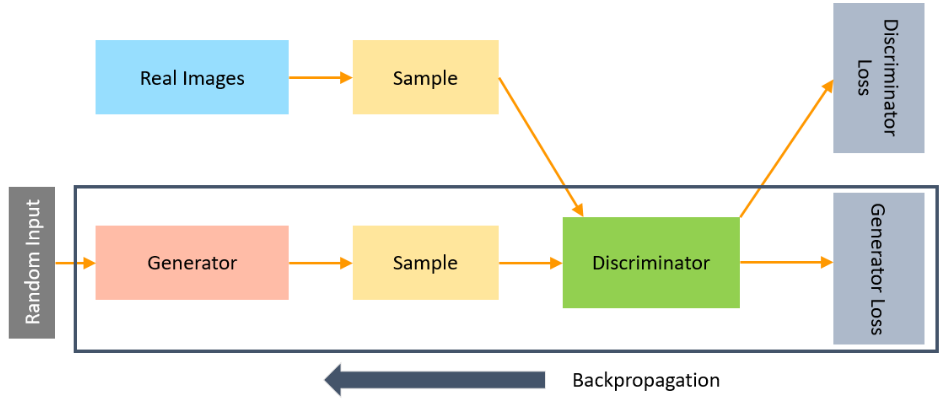
Source: Simplilearn
Discriminators
The Discriminator is a neural network that identifies real data from the fake data created by the Generator. The discriminator’s training data comes from different two sources:
- The real data instances, such as real pictures of birds, humans, currency notes, etc., are used by the Discriminator as positive samples during training.
- The fake data instances created by the Generator are used as negative examples during the training process.
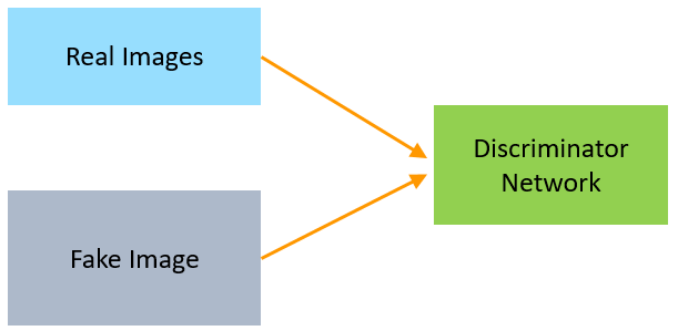
Source: Simplilearn
While training the discriminator, it connects to two loss functions. During discriminator training, the discriminator ignores the generator loss and just uses the discriminator loss.
In the process of training the discriminator, the discriminator classifies both real data and fake data from the generator. The discriminator loss penalizes the discriminator for misclassifying a real data instance as fake or a fake data instance as real.
The discriminator updates its weights through backpropagation from the discriminator loss through the discriminator network.
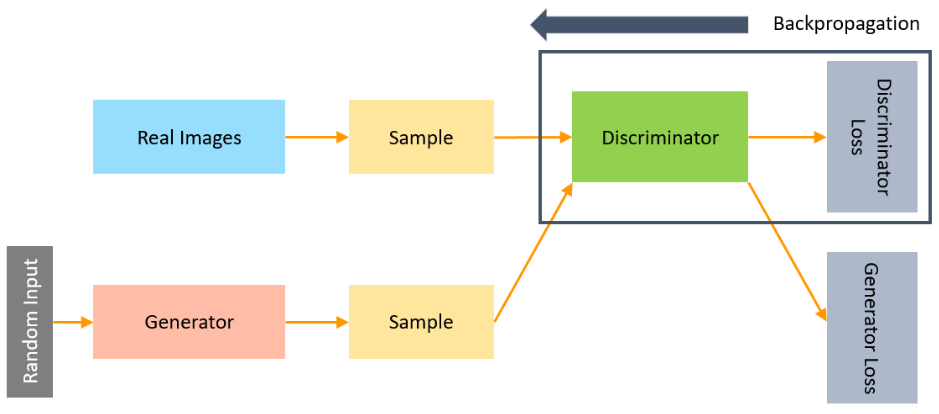
Source: Simplilearn
Types
There are many different forms of GAN implementations:
Vanilla GAN: The most basic GAN type is called a vanilla GAN. The Generator and Discriminator in this scenario are straightforward multi-layer perceptrons. Simple stochastic gradient descent is used in vanilla GAN’s approach to try and optimize the mathematical problem.
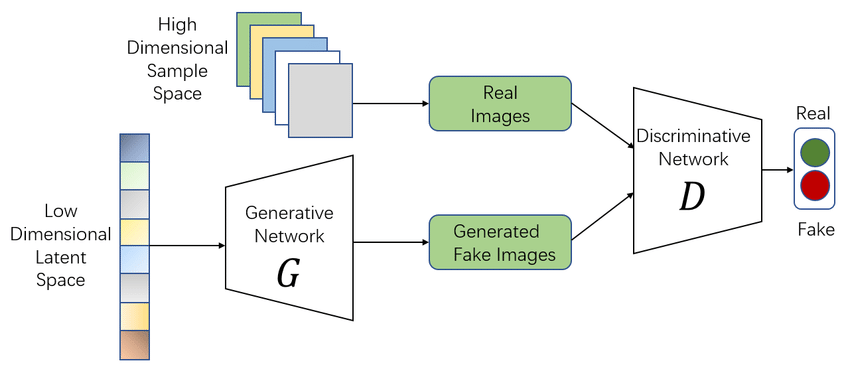
Source: Labellerr.com
Conditional GAN (CGAN): CGAN is a deep learning technique that employs a number of conditional parameters. In CGAN, the Generator is given an extra parameter, “y,” to produce the necessary data. Labels are also included in the Discriminator’s input so that it can help distinguish between authentic data and artificially generated data.
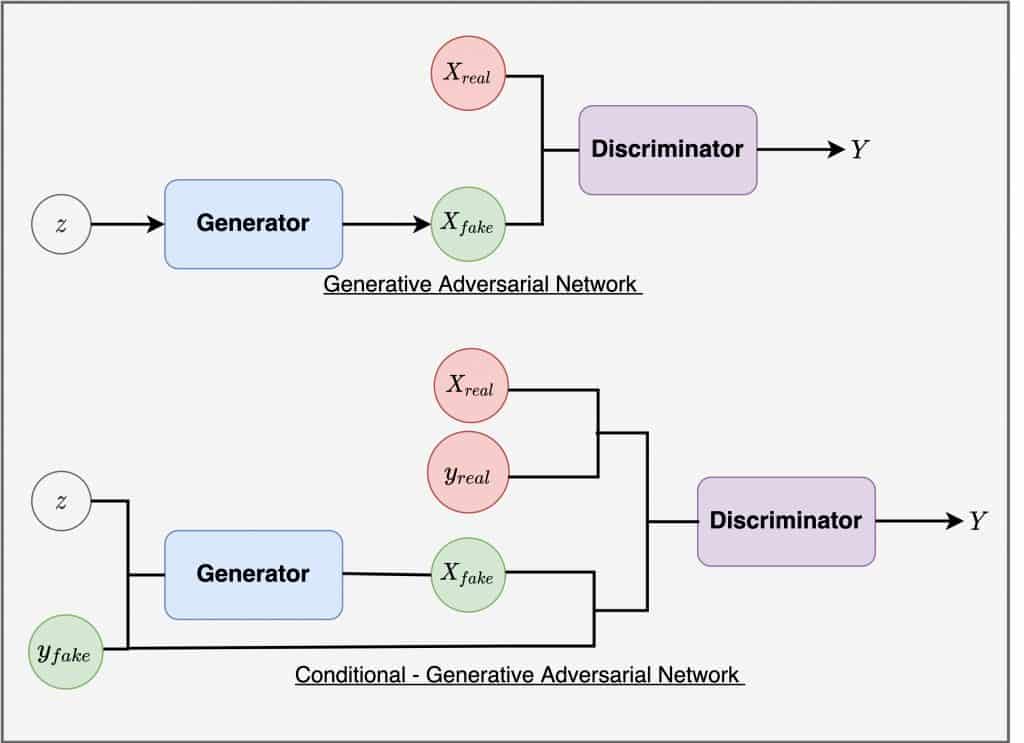
Source: Labellerr.com
Deep Convolutional GAN (DCGAN): DCGAN is among the most well-liked and effective GAN implementations. ConvNets are used instead of multi-layer perceptrons in their construction. Convolutional stride actually replaces max pooling in the ConvNets implementation. The layers are also not entirely connected.
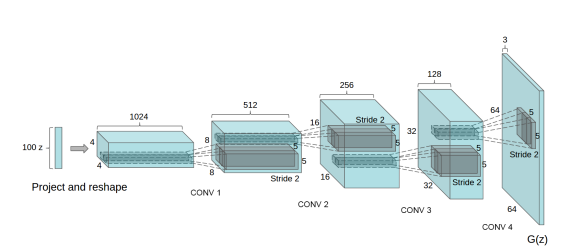
Source: Labellerr.com
Super Resolution GAN (SRGAN): As the name implies, SRGAN is a method for creating a GAN that uses both a deep neural network and an adversarial network to generate higher-resolution images. This particular sort of GAN is very helpful in enhancing details in native low-resolution photos while minimizing mistakes.
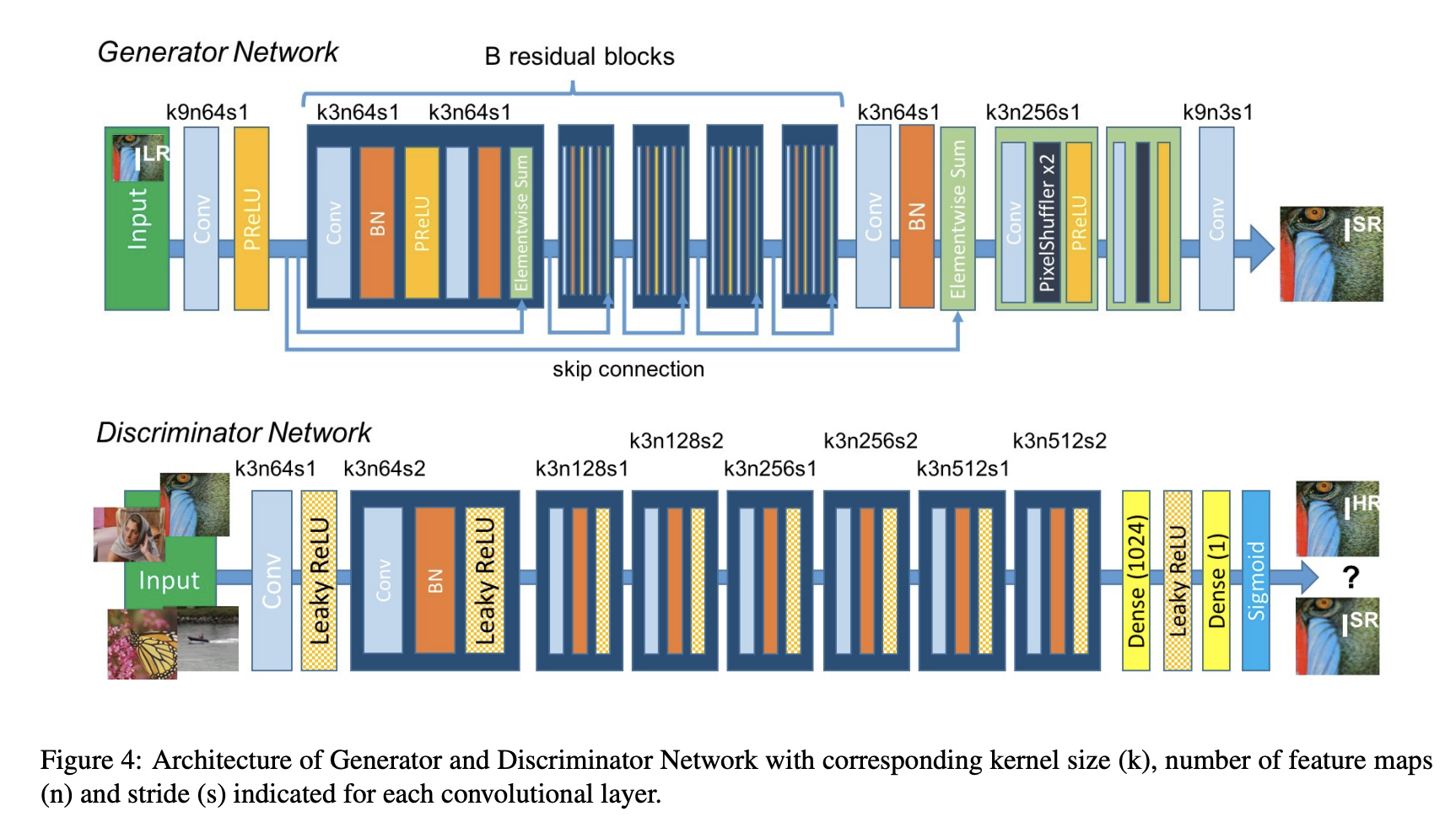
Source: Labellerr.com
Laplacian Pyramid GAN (LAPGAN): A set of band-pass pictures that are separated by an octave and a low-frequency residual make up the Laplacian pyramid, a linear invertible image representation. This method makes use of several Generator and Discriminator networks as well as various Laplacian Pyramid levels.
The major reason this method is employed is that it results in photographs of extremely high quality. The image is initially downscaled at each pyramidal layer before being upscaled at each layer once again in a backward pass. At each of these layers, the image picks up noise from the Conditional GAN until it reaches its original size.
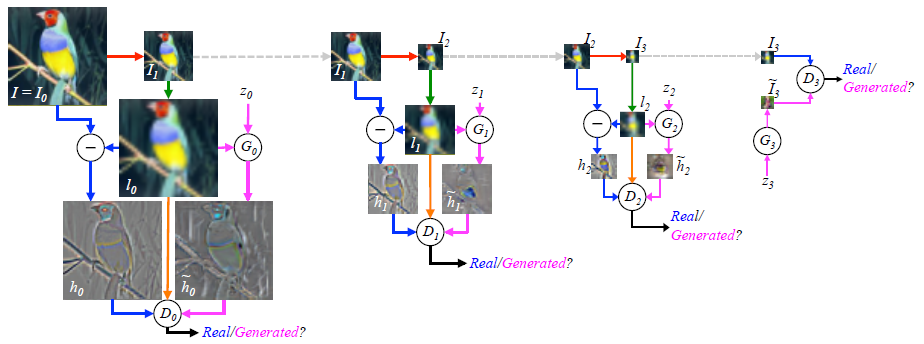
Source: Labellerr.com
AI INFLUENCERS
John Carmack ![]()
![]()
Clem Delangue ![]()
Timnit Gebru ![]()
![]()
Jensen Huang ![]()
![]()
Lila Ibrahim ![]()
![]()
Robert Miles ![]()
![]()
Kevin Scott ![]()
![]()
AI MODELS
Popular Large Language Models
ALPACA (Stanford)
BARD (Google)
Gemini (Google) ![]()
GPT (OpenAI) ![]()
LLaMA (Meta) ![]()
Mixtral 8x7B (Mistral)
PaLM-E (Google)
VICUNA (Fine Tuned LLaMA)
Popular Image Models
Stable Diffusion (StabilityAI)
Leaderboards
