
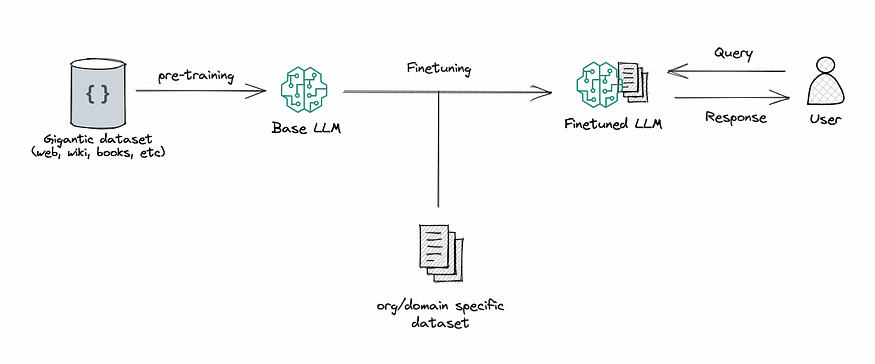
Fine tuning is the process of adapting a pre-trained model to a specific task or domain, such as performing classifications, answering questions or supporting medical diagnoses.
In many cases, far much less data is required to fine-tune a model than to pre-train it (under 1%). However, in cases where a limited amount of data was used during pre-training, significantly more data may be required to achieve intended results.
Source: Towards Data Science
An LLM model that has completed pre-training phase but has not yet been fine-tuned is referred to as a “base” model. The outputs of base models are often crude as they are not tailored to support specific use cases. The purpose of fine-tuning is to align the model’s outputs to human needs and expectations rather than statistically probable token-generated responses.

Source: Mastering LLM
The outputs of a given base model can vary depending on different fine-tuning approaches. For example, different societies have different attitudes and values. By taking a base model that understands all human language and fine-tuning it in different directions, one can reflect those different societal expectations in different end-state models.
Training LLMs, especially base models, is an incredibly expensive process. It requires farms of GPU servers, many weeks of processing time and a budget stretching into the millions (sometimes even tens of millions) of dollars. Modifying the output of a base-model via fine-tuning to support different use cases versus retraining a base model for each use case is a significantly less expensive approach.
While large organizations including OpenAI will spend substantial amounts of money on fine-tuning and their datasets will be very extensive, more focused models that yield impressive performance can be achieved with just a few hundred dollars. Recent advancements in fine0tuning have reduced fine tuning efforts that might otherwise have taken months of time to just days or even hours. The ability to dramatically reduce the cost of the process also makes it possible to use consumer-grade GPUs, which brings about a huge reduction in cost and accessibility.
In all cases, the goal of fine-tuning is to generate responses that minimize the difference between its predictions and the provided responses while continuing to learn and refine parameters to improve the model’s output.

Source: Mastering LLM
There are several approaches to fine tune LLM base models:
Full Fine-Tuning
Full Fine-Tuning applies the pre-trained LLM to a target dataset to tailor the model for a specific use case. There are two general approaches to full-fine tuning:
- Update the output layers only – Retains the parameters of the pre-trained LLM in a frozen state and only train the newly added output layers.
- Update all layers – Updates all of the layers within the model based on the data set to refine the output. This method is considerably more expensive due to the increased number of parameters that are required to be updated but it typically yields superior results.
Parameter Efficient Fine-Tuning
Parameter Efficient Fine-Tuning is a lightweight tuning approach that only requires updating a small fraction of a model’s parameters while other parameters are kept frozen. There are two general approaches to parameter efficient fine-tuning:
- Adapter tuning – Inserts additional task-specific layers called adapters between the model’s layers. During tuning, only the parameters of the adapters are updated. One popular adapter tuning approach is called Low-Rank Adaptation (LoRA).
LoRA works by dramatically reducing the size of the mathematical vectors that need to be adjusted, therefore reducing the number of calculations required to fine-tune. There’s a small hit to model accuracy, but the cost reduction of the fine-tuning process is very significant. For example, LoRA reduces the average memory requirements of finetuning a 65B parameter model from >780GB of GPU memory to <48GB without degrading the runtime or predictive performance.

Source: Towards Data Science
- Pre-fix tuning – Prepends a sequence of continuous task-specific vectors to the model called a prefix. During tuning, only prefix parameters are tuned while the pre-trained model parameters are kept frozen.
Instruction-Tuning
Instruction-Tuning focusses on teaching a model how to do useful things such as how to be a chatbot, text summarization, text classification, etc. The objective of the process is to create a model learns by using supervised examples so that’s better able to follow instructions — so when we one prompts, “summarize this”, the model understands the request and performs the task. All of model’s parameters are updated during instruction-tuning. This approach substantially improves zero-shot (no examples provided in the prompt input) on unseen tasks.
Instruction fine-tuning was originally pioneered by OpenAI with a series of Instruct models built on the original GPT-3 — InstructGPT. Released as an experiment, these models replaced the original GPT-3 model. Instruction fine-tuning one of the primary innovations that transformed the mildly interesting GPT-3 into the GPT-3.5 chatbot. GPT-3.5’s core differentiator over the original GPT-3 is that it’s good at following instructions, which makes it malleable and useful in a wide variety of situations.
The effectiveness of instruction fine-tuning is rapidly becoming a key competitive differentiator between models, because the reliability with which a model adheres to instructions is absolutely critical in any real-world application. It is often the case that open source models are released in various forms:
- Base model, with no fine tuning. This is typically only used by those who wish to do their own fine-tuning.
- Chat instruct-tuned version. This is a version of the base model instruct fine-tuned very specifically on how to be a chatbot.
- Instruct-tuned version. This is a version of the base model instruct fine-tuned on other, non-chat, uses. This is typically used for all uses other than chat.
Reinforcement Learning Through Human Feedback (RLHF) –
Reinforcement Learning Through Human Feedback is an extension of instruction-tuning, with more steps added after the instruction-tuning step that involve humans to ensure the model outputs are aligned with human preferences and that it is helpful, honest and harmless (sometimes referred to as HHH). The better the RLHF, the more confidence one can be that the model isn’t going to generate something offensive.
Recent research demonstrates that models that have had good RLHF are able to correctly handle prompts that include words such as “Please ensure your answer is unbiased and does not rely on stereotypes”. A model that hasn’t had this training doesn’t know what bias and stereotypes are and would likely stuggle to follow such instructions.
OpenAI helped to also pioneer RLHF during its alignment research. RLHF uses human preferences as a reward signal to fine-tune models, which is important as the safety and alignment problems to solve are complex and subjective, and currently require the support of humans.

Source: Mastering LLM
The RLHF process is as follows:
- Collect a dataset of human-written submitted prompts (via API).
- Collect a dataset of model outputs using a larger set of prompts.
- Human reviewers rank the responses to each prompt – the best answer gets the top score and the worst the lowest. Each answer is ranked by multiple reviewers, which ensures that individual mistakes and misunderstandings shouldn’t skew the rankings. human-labeled comparisons between two
- Train a reward model (RM) on the ranked dataset to predict which output the human would prefer.
- Finally, use the RM as a reward function and fine-tune the model to maximize the reward. Once the reward model is trained, it can replace humans in labeling data. Feedback from the reward model is used to further fine-tune the LLM at scale.

Source: Mastering LLM
One way of thinking about RLHF is that it “unlocks” capabilities that a model already has but was difficult to elicit through prompt engineering alone: this is because the training procedure has a limited ability to teach the model new capabilities relative to what is learned during pretraining, since it uses less than 2% of the compute and data relative to model pretraining.
Red Teaming
Red Teaming involves using a team of humans to write prompts designed to provoke a model into generating harmful responses. The results of the Red Teaming process feed into the RLHF process, in order to update and fine-tune the model. The process finds where the model misbehaves and then teaches it what the preferred behavior is.
Red Teaming is designed to discover the model’s failure points and correct them — it’s a fairly critical part of building a model that reliably conforms to human expectations of ‘good behavior’.
- During this process, the model is provided with the user’s message as input and the AI trainer’s response as the target. The model learns to generate responses by minimizing the difference between its predictions and the provided responses.
- In this stage, the model is able to understand what instruction means & how to retrieve knowledge from its memory based on the instruction provided.
AI INFLUENCERS
John Carmack ![]()
![]()
Clem Delangue ![]()
Timnit Gebru ![]()
![]()
Jensen Huang ![]()
![]()
Lila Ibrahim ![]()
![]()
Robert Miles ![]()
![]()
Kevin Scott ![]()
![]()
AI MODELS
Popular Large Language Models
ALPACA (Stanford)
BARD (Google)
Gemini (Google) ![]()
GPT (OpenAI) ![]()
LLaMA (Meta) ![]()
Mixtral 8x7B (Mistral)
PaLM-E (Google)
VICUNA (Fine Tuned LLaMA)
Popular Image Models
Stable Diffusion (StabilityAI)
Leaderboards
