
Recurrent Neural Networks are neural networks that are designed to model sequence data such as speech recognition, language prediction and stock predictions.
RNNs overcome the issue of fixed input layer sizes. It would be difficult to input different sentences into a neural network as each sentence is comprised of a different number of words. If one was to expand the number of nodes in the input layer to support the largest sentence, the network size would grow significantly. RNNs solve for this by breaking down the input into consumable bites and iterating over the data sequentially. RNNs predict outcomes via storing the output of each hidden layer and then using the output of that layer as part of the input to the next hidden layer of the network. They use the same weights for each element of the sequence, decreasing the number of parameters and allowing the model to generalize to sequences of varying lengths.
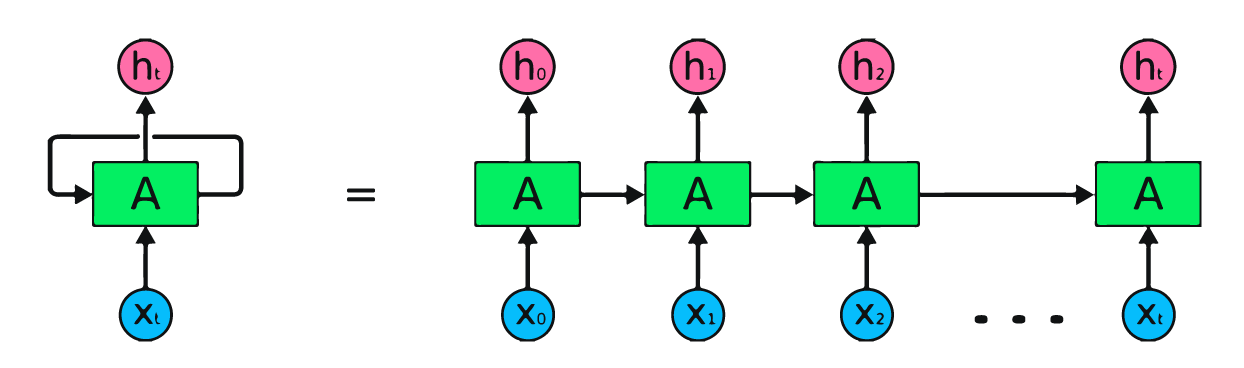

As with any neural network, data is encoded and fed into the network via the input layer. For example, if a user enters the prompt “What time is it?” into the network, the RNN will first break up the words of the sentence:

Then the RNN encodes the first word (“What”) and produces an output of the first layer:
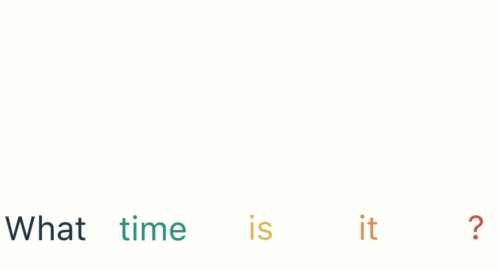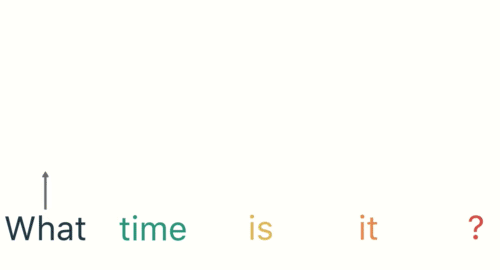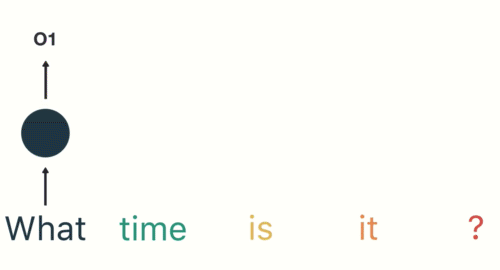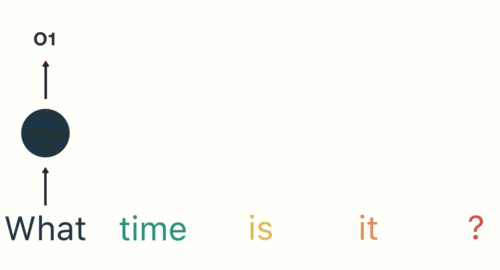
In the second hidden layer, the second word (“time”) is applied to the output of the first layer (“What”):
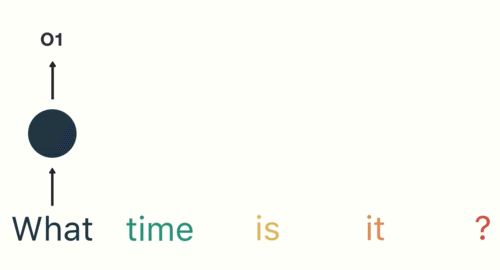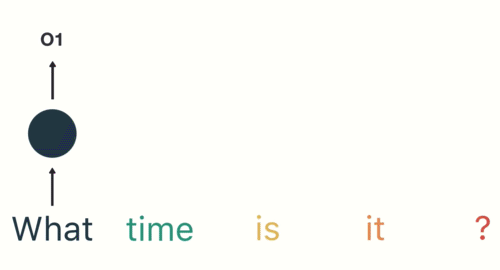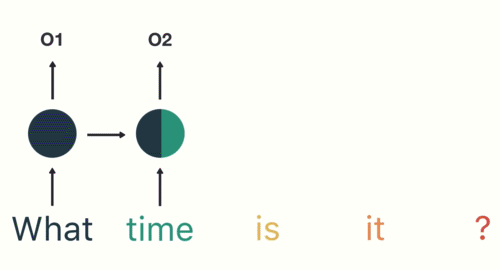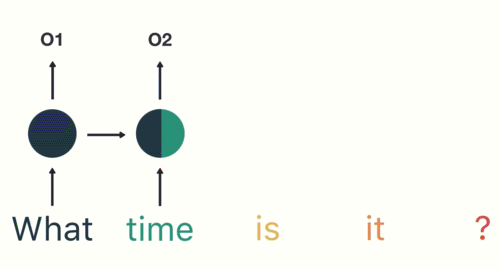
This process is repeated in each subsequent layer for each word in the sentence:
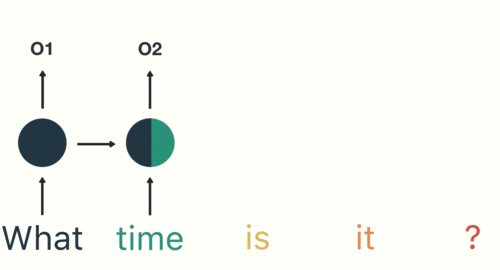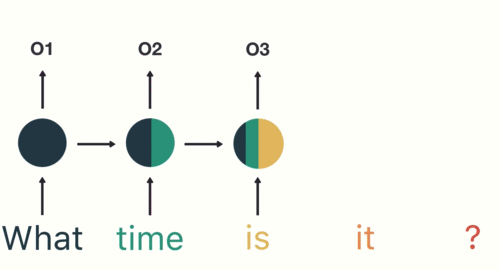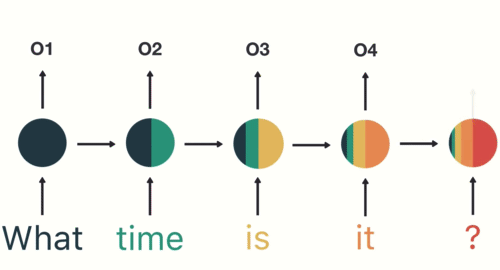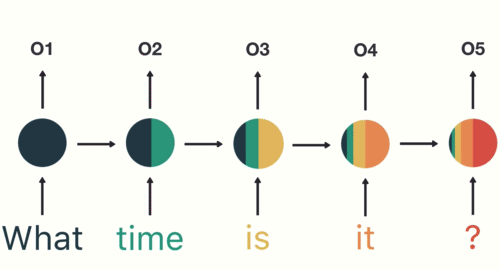
The final output is created from the sequence and is applied to a feed-forward network to classify the intent of the sentence.
Depending on the network objective, RNNs can take different forms:

Source: Kaparthy GitHub
Each rectangle is a vector and arrows represent functions (e.g. matrix multiply). Input vectors are in red, output vectors are in blue and green vectors hold the RNN’s state (more on this soon). From left to right:
- Vanilla mode of processing without RNN, from fixed-sized input to fixed-sized output (e.g., image classification).
- Sequence output (e.g., image captioning takes an image and outputs a sentence of words).
- Sequence input (e.g., sentiment analysis where a given sentence is classified as expressing positive or negative sentiment).
- Sequence input and sequence output (e.g., Machine Translation: an RNN reads a sentence in English and then outputs a sentence in French).
- Synced sequence input and output (e.g., video classification where we wish to label each frame of the video).
Notice that in every case are no pre-specified constraints on the lengths sequences because the recurrent transformation (green) is fixed and can be applied as many times as we like.
Similar to other feed forward neural networks, RNNs network leverage backpropagation to train and refine the node parameters to improve the network model. As the input gets bigger, words (layers) closer to the beginning of the model (input layer) are not as influenced by the gradient descent parameter refinement algorithm to improve the loss. To overcome the vanishing gradient problem as illustrated by the descending distribution of colors, technique called LSTM (Long Short Term Memory) or GRUs (Gated Recurring Units) are applied. These approaches aim to manage errors more discretely at each neuron.
AI INFLUENCERS
John Carmack ![]()
![]()
Clem Delangue ![]()
Timnit Gebru ![]()
![]()
Jensen Huang ![]()
![]()
Lila Ibrahim ![]()
![]()
Robert Miles ![]()
![]()
Kevin Scott ![]()
![]()
AI MODELS
Popular Large Language Models
ALPACA (Stanford)
BARD (Google)
Gemini (Google) ![]()
GPT (OpenAI) ![]()
LLaMA (Meta) ![]()
Mixtral 8x7B (Mistral)
PaLM-E (Google)
VICUNA (Fine Tuned LLaMA)
Popular Image Models
Stable Diffusion (StabilityAI)
Leaderboards
