
Artificial Neural Networks (ANNs) are a subset of machine learning and enable the discipline of deep learning.

Image Source: IBM
Neural networks are used to create software that can learn and make decisions like humans. They are composed of many interconnected processing nodes, or neurons, that can learn to recognize patterns, akin to the human brain.
One of the advantages of neural networks is that they can be trained to recognize patterns in data that are too complex for traditional computer algorithms. While traditional computer programs are deterministic, neural networks, like all other forms of machine learning, are probabilistic, and can handle far greater complexity in decision-making.
Neurons within neural networks are modeled from the structure of biological neurons:

Source: Applied Go
A neural net consists of thousands or even millions of simple processing nodes that are densely interconnected. Most of today’s neural nets are organized into layers of nodes, and they’re “feed-forward,” meaning that data moves through them in only one direction. An individual node might be connected to several nodes in the next layer before it, from which it receives data, and several nodes in the next layer, to which it sends data.
The neurons of neural networks are arranged in layers termed input, hidden, and output layers.

Image Source: IBM
The input layer of a neural network is composed of artificial input neurons and brings the initial data into the system for further processing by subsequent layers of artificial neurons. The input layer is the very beginning of the workflow for the artificial neural network. The hidden layer in an artificial neural network is a layer in between input layers and output layers.
As data is fed through the input layer, each node within the network leverages parameters (also called weights and biases) and a formula (called an activation function; different types of activation functions can be applied) to calculate the value of each neural input. If the output of the activation function calculation exceeds a set threshold, the value is passed onto the next layer within the network. If the calculation is less than the preset threshold, the value is discarded and the information does not flow to the next layer.

The values of the nodes within the hidden layer are calculated by multiplying the value from the input with the weights (and biases) using dot product multiplication:
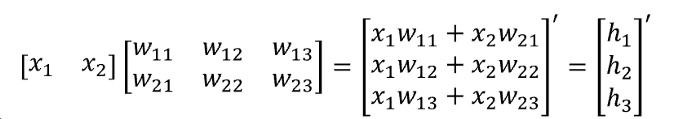
Source: Turing
Data traverses the network until it computes a final result in the output layer. The output layer receives its input from the last hidden layer.
Neural networks require training to be accurate. Typically, the weights of the model are set randomly. For every training example, a forward pass (i.e., epoch) is performed using the initial randomly set weights. The final output of the model is compared with the target in the training data to calculate the error. The error, or deviation from the target, is calculated using a loss function. The loss function provides guidance as to where and how to adjust the model’s weights. Training epochs are performed to continually assess the error and improve the model’s output.
To improve the loss (error) of the network , backpropagation is performed to traverse backwards through and refine all of the parameters (i.e., weights) of the neurons in the network. The process of adjusting the parameters of each neuron to minimize the output error is called gradient descent. The gradient descent calculation (algorithm) is applied to each neuron of every layer starting with the layer closest to the output layer to reduce the overall output loss (error). Because the parameter adjustments of the nodes within each layer of the network are dependent on the adjustment of the layer before it (moving from end to beginning), adjustment to the layers towards the end of the network (the output layer) are more significant than those towards the front (the input layer) of the network. This issue is known as the vanishing gradient problem. To mitigate the impact of the vanishing gradient, various techniques are applied to different types of networks including changing the types of activation functions and applying approaches that add “memory” to the network.
The probabilistic nature of neural networks is what makes them so powerful. With enough computing power and labeled data, neural networks can solve for a huge variety of tasks. One of the challenges of using neural networks is that they have limited interpretability, so they can be difficult to understand and debug. Neural networks are also sensitive to the data used to train them and can perform poorly if the data is not representative of the real world.
Deep learning is considered a neural network with at least two hidden layers. Deep learning neural networks are receiving significant attention of late as it is the technology that underpins many large language models (LLMs) including ChatGPT.
AI INFLUENCERS
John Carmack ![]()
![]()
Clem Delangue ![]()
Timnit Gebru ![]()
![]()
Jensen Huang ![]()
![]()
Lila Ibrahim ![]()
![]()
Robert Miles ![]()
![]()
Kevin Scott ![]()
![]()
AI MODELS
Popular Large Language Models
ALPACA (Stanford)
BARD (Google)
Gemini (Google) ![]()
GPT (OpenAI) ![]()
LLaMA (Meta) ![]()
Mixtral 8x7B (Mistral)
PaLM-E (Google)
VICUNA (Fine Tuned LLaMA)
Popular Image Models
Stable Diffusion (StabilityAI)
Leaderboards
