Stability releases its first foundation model for generative video based on the image model Stable Diffusion. Their code for Stable Video Diffusion is available on their GitHub repository & the weights required to run the model locally can be found on their Hugging Face page.
Their video model can be easily adapted to various downstream tasks, including multi-view synthesis from a single image with finetuning on multi-view datasets. They are planning a variety of models that build on and extend this base, similar to the ecosystem that has been built around stable diffusion.
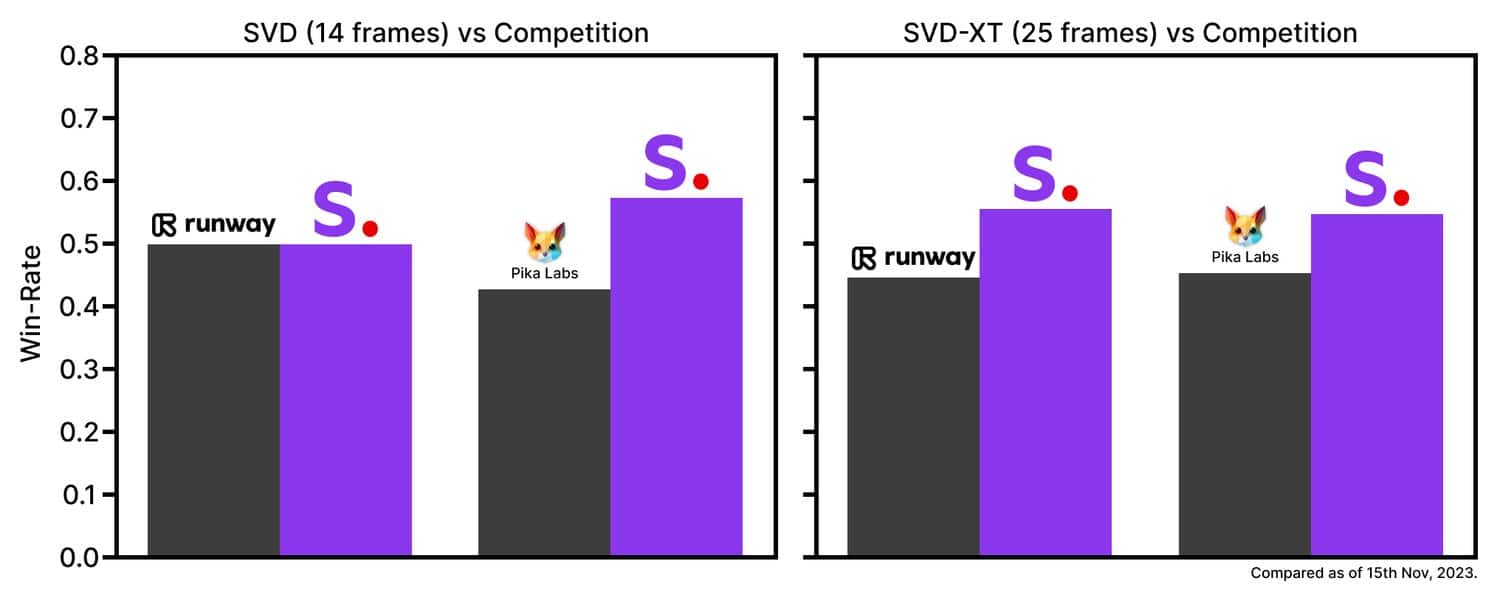
Stable Video Diffusion is released in the form of two image-to-video models, capable of generating 14 and 25 frames at customizable frame rates between 3 and 30 frames per second. At the time of release in their foundational form, through external evaluation, they have found these models surpass the leading closed models in user preference studies.